jotang招新8-1
🔥安装Anaconda
嘛~这一步没有想象中的顺利,先找了教程大概看了一下觉得没什么问题,就直接大胆安装了,用的是清华源,一路下来完成后输入conda,就报错了捏
查找原因应是电脑上已经有python
于是一不做二不休,把他给卸了,环境变量里也先给删除
然后就好了
按照招新题的提示稍微了解神经网络的基本概念和pytorch等
-
神经网络的基本概念:
官网定义如下:神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。每个节点代表一种特定的输出函数,称为激励函数(activation function)。每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
-
pytorch是什么:
大概康了康,pytorch是一个深度学习的框架,
监督学习/无监督学习
- 监督学习supervised learning:监督学习是学习一个模型,让模型能够对任意给定的输入,对他的输出做一个预测,直白点就是用训练集训练,然后用模型测试样本集
- 无监督学习unsupervised learning:没有给定的标准,自动对输入的资料进行分类,然后寻找模型和规律,也就是说在学习的过程中,每个训练元组的类标号是未知的,并且通过学习所形成的类的个数或集合也不知道。典型的无监督学习:聚类等
监督学习需要每个样本都有标签,无监督学习则不需要。所以后面也出现了弱监督学习和半监督学习,并非所有样本都有标签。
分类器/预测器
- 分类器:
分类器是数据挖掘中对样本进行分类的方法的统称,包含决策树,逻辑回归,朴素贝叶斯,神经网络等 分类器的构造和实施大体会经过以下几个步骤: 选定样本(包含正样本和负样本),将所有样本分成训练样本和测试样本两部分。 在训练样本上执行分类器算法,生成分类模型。 在测试样本上执行分类模型,生成预测结果。 根据预测结果,计算必要的评估指标,评估分类模型的性能。 几种基本的分类器: 决策树分类器;选择树分类器;证据分类器—选择树分类器与决策树分类器比较相近,但是前者在选择节点处可以考虑多种情况,将多种因素放入一个选择节点中,而决策树分类器一个节点一次最多只能选取一个属性作为考虑对象。 证据分类器就是通过检查在一个给定属性上某个特定的结果发生的可能性来对数据进行分类。比如一个正在打着一把伞的人,有70%是女性,30%是男性。
- 预测器: 接收一个简单的输入,做出应有的预测,再输出结果
独热码:
One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
他可以将定性的数据编码为定量的数据
在机器学习中广泛用于对离散型的分类数据预处理操作。如特征性别,即可分为三类:男、女和其他。用计算机二进制表达([1,0,0],[0,1,0],[0,0,1])
one-hot编码详解参考的是下面这篇文章:
向量化
- 可以将高度重复的计算组织成 并行的向量运算,对于 简化代码,加速运算 有着非常重要的作用。简单来说就像是把多次for循环变成一次计算
神经元/输入层/隐藏层/输出层
-
神经元:是构成神经网络的基本单元。就像是人脑里的神经元,接受输入信号,并产生输出
.png)
-
输入层/隐藏层/输出层:上面是一个经典的神经网络,红色的是输入层,绿色的代表输出层,紫色的是隐藏层,也叫做中间层
参考链接如下:
卷积convolution
从百度上抄了个定义:在泛函分析中,卷积、旋积或褶积(英语:Convolution)是通过两个函数 f和g生成第三个函数的一种数学运算,其本质是一种特殊的积分变换,表征函数f与g经过翻转和平移的重叠部分函数值乘积对重叠长度的积分。
有点抽象
目前我觉得他就是一种运算方法,就像加减乘除一样
“卷”是指函数翻转,也有滑动的意味?
“积”是指积分/加权求和
很详细的讲解什么以及为什么是卷积(Convolution)-面包板社区
激活函数
抄来的定义:
激活函数(Activation Function)是一种添加到人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。类似于人类大脑中基于神经元的模型,激活函数最终决定了要发射给下一个神经元的内容。
在人工神经网络中,一个节点的激活函数定义了该节点在给定的输入或输入集合下的输出。
我目前理解是:激活函数就是一个用于神经网络中的函数,这个函数接收输入的数据,然后产生输出数据,并输出发送给下一个神经元。
参考链接:
[深度学习领域最常用的10个激活函数,一文详解数学原理及优缺点](https://finance.sina.com.cn/tech/2021-02-24/doc-ikftssap8455930.shtml#:~:text=激活函数(Activation Function)是,输入集合下的输出。)
权重/权重更新
- 权重:不同神经元的连接被赋予不同的权重,权重代表的是一个节点对另一个节点的影响大小
- 权重更新:
梯度/学习率/损失函数/过拟合
- 梯度:
- 学习率:
- 损失函数:这是一个非负实数函数,用来量化模型预测和真实标签之间的差异。
- 过拟合:overfitting,过度拟合。我们的训练样本往往是很小的(和真实情况相比),不能很好的反映全部数据的真实分布,这样就可能使得我们训练出来的模型在我们的训练集上错误率很低,但是对于未知数据错误率就升高了。
- 欠拟合: 没有充分学习训练集的特征
训练集/测试集
可以把一组样本构成的集合称为数据集,然后数据集呢又可以分为训练集和测试集。训练集中的样本是用来训练模型的,测试集中的样本用来检验训练好的模型
神经网络性能评价指标:
最常用的是准确率,错误率,精确率和召回率宏平均,微平均,交叉验证
接下来就正式开始做招新题目啦
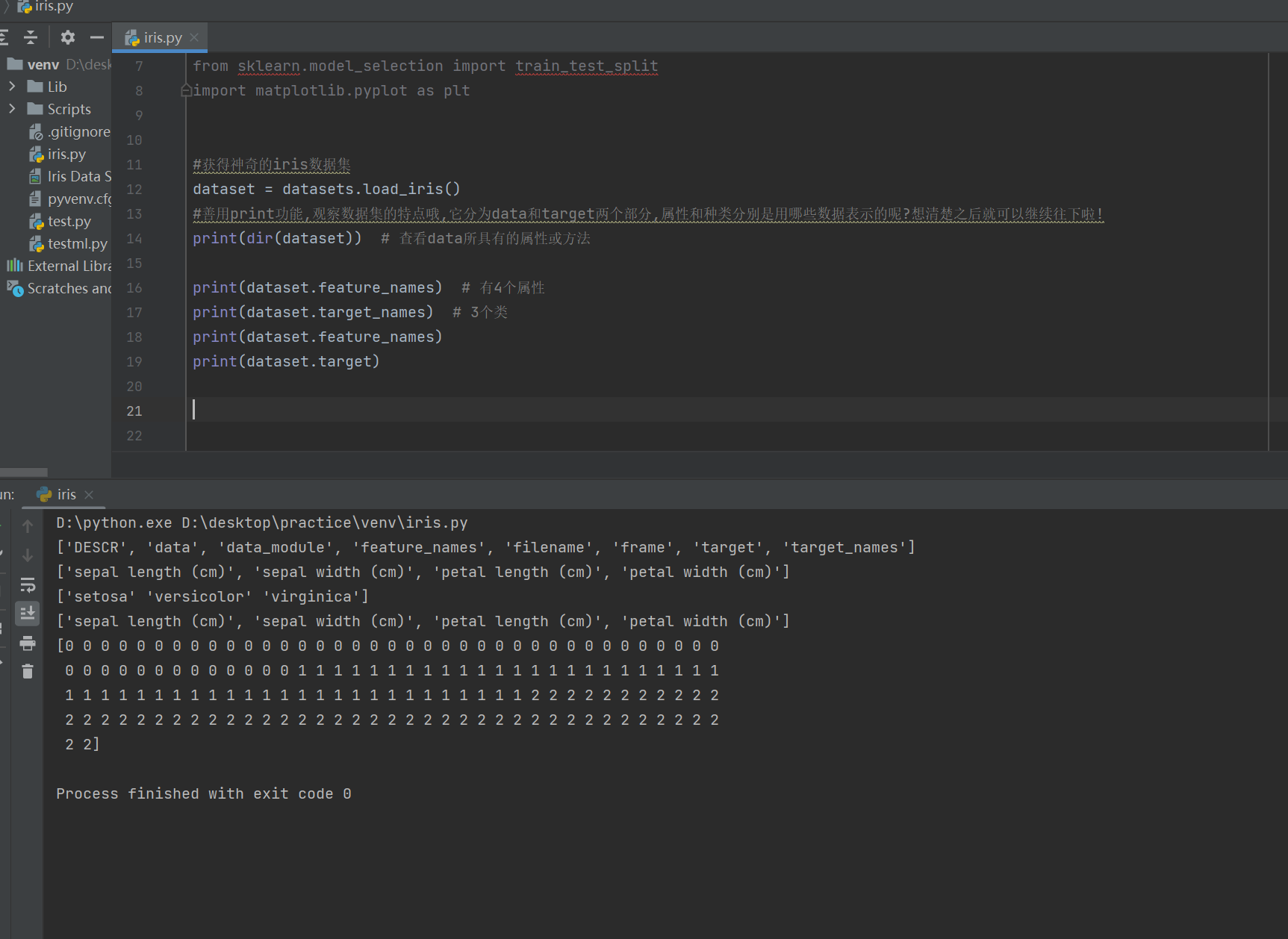
刚开始的时候对这个iris数据集做了一个了解
Iris Data Set(鸢尾属植物数据集)是我现在接触到的历史最悠久的数据集,它首次出现在著名的英国统计学家和生物学家Ronald Fisher 1936年的论文《The use of multiple measurements in taxonomic problems》中,被用来介绍线性判别式分析。在这个数据集中,包括了三类不同的鸢尾属植物:Iris Setosa,Iris Versicolour,Iris Virginica。每类收集了50个样本,因此这个数据集一共包含了150个样本。
这个数据集测量了所有150个样本的4个特征,分别是:
- sepal length(花萼长度)
- sepal width(花萼宽度)
- petal length(花瓣长度)
- petal width(花瓣宽度)
我们可以直接利用Python中的机器学习包scikit-learn直接导入该数据集
对数据集的了解到此,接下来就正式试着填完?代码吧
1 | |
步骤如下:
二八划分测试集与训练集
因为题目中已经 from sklearn.model_selection import train_test_split,所以直接通过sklearn实现
1 | |
利用pytorch把数据张量化
1 | |
relu激活函数:
1 | |
相比于其它激活函数来说,ReLU有以下优势:对于线性函数而言,ReLU的表达能力更强,尤其体现在深度网络中;而对于非线性函数而言,ReLU由于非负区间的梯度为常数,因此不存在梯度消失问题(Vanishing Gradient Problem),使得模型的收敛速度维持在一个稳定状态。这里稍微描述一下什么是梯度消失问题:当梯度小于1时,预测值与真实值之间的误差每传播一层会衰减一次,如果在深层模型中使用sigmoid作为激活函数,这种现象尤为明显,将导致模型收敛停滞不前。
————————————————
版权声明:本文为CSDN博主「对半独白」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/cherrylvlei/article/details/53149381
搭建神经网络(2个隐藏层1个输出层)
代码补充到这里的时候发现前面的了解实在太过于浅显,于是又去看了隐藏层输出层相关的具体知识